你有没有想过:为什么同样的 AI 模型,在不同系统中的表现天差地别?
当你让 AI 帮你写一段代码,有时它能完美完成任务,有时却连基本的逻辑都搞错。
这背后隐藏着一个被很多人忽视的问题:如何构建一个真正可靠的智能体系统?
今天,我想分享一篇文章来深入探讨这个话题。这篇介绍了将智能体系统准确率提升 50% 的实用模式,以及它们所带来的成本代价。以下内容翻译自 《Agentic System Patterns That Increased Accuracy by 50% (And What They Cost)》。
智能体系统已经开始被部署用于处理复杂任务:构建软件、进行研究、分析数据和自动化工作流程。但随着它们从原型走向生产环境,团队面临着一个根本性问题:如何构建一个能够可靠处理任何任务的智能体系统?
答案不仅仅是更好的提示词或更复杂的模型,而是要理解三个关键维度之间的权衡:
成本 - API 调用、计算资源、基础设施
延迟 - 任务完成时间、用户体验
准确率 - 正确性、可靠性、边界情况处理
真相是,大多数提高准确率的技术也会增加成本和延迟。多步推理、并行验证、自我修正循环——它们都能让系统变得更好,但代价不菲。关键在于知道何时付出这个代价,以及如何在你的约束范围内进行优化。
这篇文章提炼了在生产环境中构建智能体系统的经验教训。每个技巧都包含对成本、延迟和准确率的具体影响指标,以及何时应用的指导原则。读完本文后,你将拥有一个框架,可以就智能体系统架构做出明智决策。
注:这篇文章的灵感来自于最近使用 Blackbox AI 完成多个编码任务的经历,观察到他们的自主智能体如何处理规划、执行和自我修正(这已是智能体系统中常见的模式)。让我想要记录下使智能体系统在生产环境中工作的底层模式。
评估标准:成本、延迟和准确率
构建智能体系统时,每个决策都会影响这三个维度。理解如何衡量和平衡它们对于生产系统至关重要。
成本
含义: 运行智能体系统的总财务支出。
组成部分:
API 成本 - LLM API 调用(输入/输出 Tokens)、Embedding API、视觉 API
计算成本 - 服务器基础设施、容器编排、数据库查询
基础设施成本 - 存储、网络、监控工具
数据成本 - 检索系统、向量数据库、数据处理管道
如何衡量: 跟踪每次请求的成本、月度支出和每次成功任务完成的成本。成本因模型选择、上下文长度、API 调用次数和基础设施要求而有很大差异。
延迟
含义: 从用户提交任务到收到最终结果的时间。
组成部分:
LLM 推理时间 - 模型生成延迟(因模型和上下文长度而异)
工具执行时间 - API 调用、数据库查询、代码执行
网络延迟 - API 往返、数据检索
顺序处理 - 等待前序步骤完成
如何衡量: 跟踪端到端延迟(p50、p95、p99)、每步时间和用户感知的等待时间。可接受的延迟取决于你的用例——实时系统的要求比批处理更严格。
准确率
含义: 系统输出的正确性和可靠性。
组成部分:
任务完成率 - 成功完成的任务百分比
输出质量 - 结果的正确性、边界情况处理
错误率 - 幻觉、工具使用错误、执行失败
一致性 - 相似输入之间的可重复性
如何衡量: 使用特定任务的指标(代码正确性、答案准确性)、人工评估、自动化测试和错误跟踪。目标准确率取决于你的领域和错误的代价。
准确率 = f(成本, 延迟)
决策框架:何时使用什么
在深入具体技术之前,有一个框架可以帮助你根据约束条件和需求决定应用哪些技术。
步骤 1:定义约束条件
首先明确定义你的约束条件:
成本预算: 你的每次请求成本或月度预算是多少?
延迟要求: 你的可接受响应时间是多少?(实时 <2 秒,准实时 <10 秒,批处理可以是分钟/小时)
准确率要求: 你需要什么准确率水平?(取决于错误代价:高风险需要 95% 以上,原型可以容忍 70-80%)
步骤 2:评估任务复杂度
评估你的任务:
简单任务: 单步、直接的操作(分类、提取、简单 API 调用)
中等复杂度: 具有明确依赖关系的多步任务(数据处理管道、多工具工作流)
高复杂度: 需要推理、规划或处理不确定性的任务(研究、代码生成、复杂问题解决)
步骤 3:选择起点
对于简单任务:
从思维链开始(如果需要推理)
跳过规划器-执行器(开销不划算)
跳过验证智能体(除非是高风险任务)
考虑使用文件系统以增强可观察性
对于中等复杂度:
使用规划器-执行器架构
为推理密集型步骤添加思维链
使用文件系统进行状态管理
在关键决策点考虑验证智能体
对于高复杂度:
使用规划器-执行器架构(必不可少)
添加验证智能体(计划验证 + 关键里程碑)
对关键输出考虑多个智能体
始终使用文件系统进行状态和调试
全程使用思维链
步骤 4:根据结果迭代
测量 基线(成本、延迟、准确率)
应用 技术,一次一个
评估 对所有三个维度的影响
优化 移除不提供足够价值的技术
记住要从简单开始,测量一切,只在提供明确价值时才增加复杂性。
生产技术
1. 规划器-执行器架构
含义: 将智能体分解为两个专门的组件:一个将任务分解为子任务的规划器,和一个执行这些子任务的执行器。
工作原理:
规划器智能体: 接收高层任务并生成包含子任务、工具选择和参数的结构化计划
执行器智能体: 接收计划并使用指定的工具按顺序执行每个步骤
替代方案: 使用单个智能体在一次调用中生成计划(包括工具选择和参数),然后执行它
示例:
真实案例: Blackbox AI 的自主编码智能体使用这种模式进行代码生成。它解释目标,将其转换为有序的文件编辑计划,然后通过编写和修改代码来执行该计划。明确的规划→执行分离帮助它更可靠地处理多步任务。
对评估标准的影响:
成本: +1.5-2x(额外的规划 LLM 调用,但执行更高效)
延迟: +500ms-2s(规划开销,但更好的任务完成减少了重试)
准确率: +20-30%(明确的规划减少错误,更好的工具选择)
何时使用:
从明确规划中受益的复杂、多步任务
工具选择至关重要的任务
当你需要可解释、可调试的工作流时
对于开销不划算的简单、单步任务应避免使用
2. 思维链提示
含义: 一种提示工程技术,要求模型在得出最终答案之前展示其推理过程。
工作原理:
添加诸如"逐步思考"或"展示你的推理"之类的指令
提供具有明确推理链的少样本示例
模型生成中间推理步骤,然后生成最终答案
与少样本示例结合使用时效果尤其好
示例:
真实案例: 这种模式在生产工作流中很常见,如调试和根本原因分析,其中即使最终答案很短,中间推理也能减少错误。
对评估标准的影响:
成本: +1.3-1.8x(推理步骤增加 30-80% 的输出令牌)
延迟: +200ms-1s(由于更多令牌导致的更长生成时间)
准确率: +15-25%(特别是在复杂推理任务、数学、逻辑方面)
何时使用:
复杂推理任务(数学、逻辑、多步问题)
当你需要调试模型思维时
从明确的中间步骤中受益的任务
对于不需要推理开销的简单分类或提取任务应避免使用
额外好处: 思维链在切换不同模型时提高鲁棒性,因为推理步骤使过程更加透明和可调试。
3. 验证智能体的战略使用
含义: 使用单独的智能体来验证计划或输出,并提供改进反馈。
工作原理:
计划验证: 验证器在执行前审查规划器的输出,提供反馈,规划器进行改进
输出验证: 在每个执行步骤后,验证器检查结果,提供反馈,规划器调整剩余步骤
不要验证每个 LLM 调用。要战略性地考虑验证在何处增加最大价值
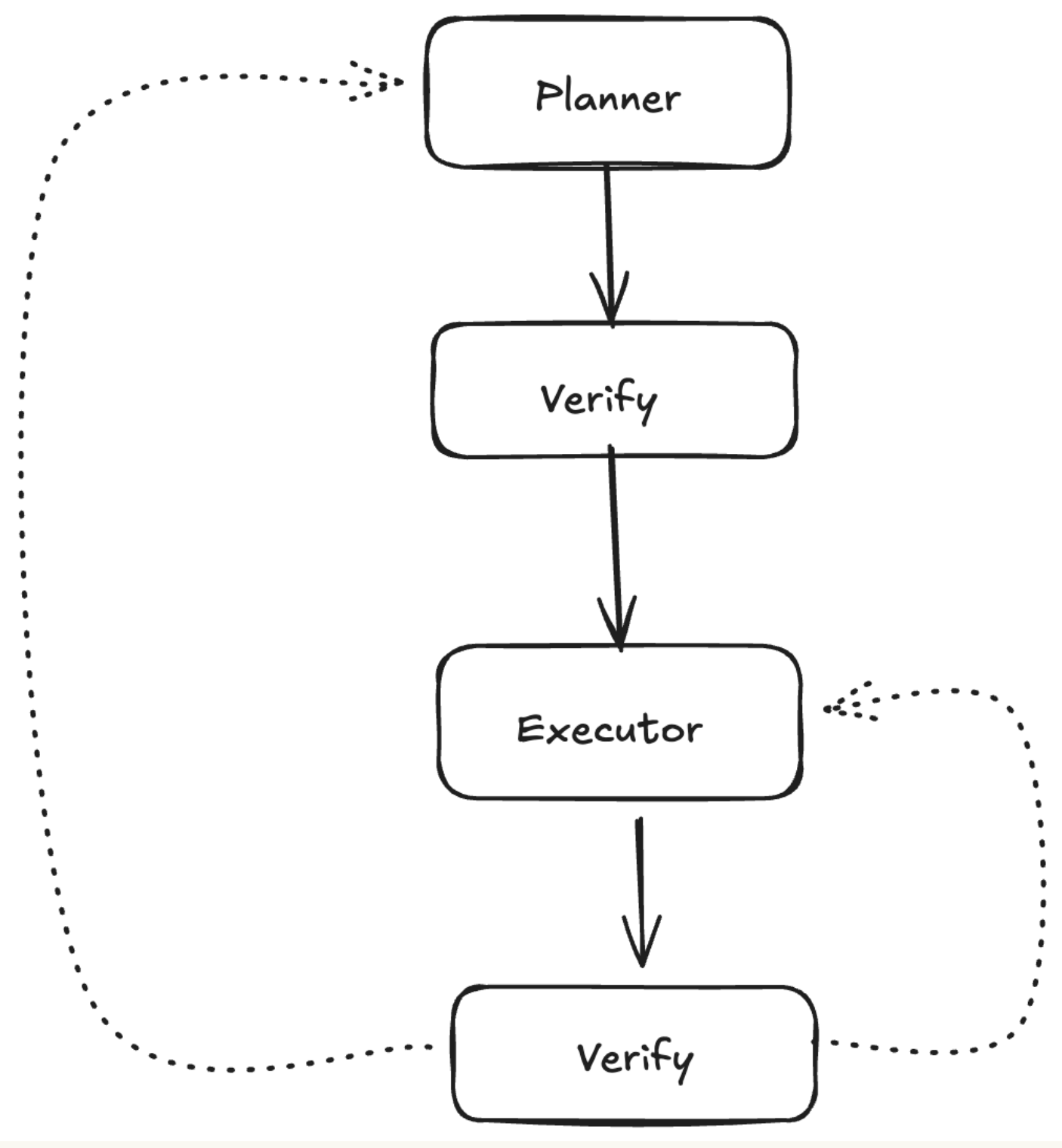
示例:
真实案例: Blackbox AI 的自主智能体使用自我修正作为内置的验证机制。生成代码后,它会自动测试和验证更改是否按预期工作。如果出现错误,它会分析问题、调试代码并尝试新方法——本质上是作为一个连续循环中自己的验证智能体。这种自我修正持续到任务完成,展示了验证如何直接集成到执行周期中,而不是作为一个单独的步骤。
对评估标准的影响:
成本: +1.5-3x(额外的验证 LLM 调用,因频率而异)
延迟: 每个验证步骤 +1-3s(模型调用 + 反馈循环)
准确率: +25-40%(及早发现错误,提高计划质量)
何时使用:
错误代价高昂的高风险任务
从审查中受益的复杂计划
当你无法承担执行失败时
避免验证每一个步骤。专注于关键决策点或最终输出
最佳实践:
在执行前验证计划一次(及早发现问题)
在关键里程碑验证输出,而不是每一步
对简单检查使用轻量级验证,对复杂决策使用完整验证
4. 使用多个智能体并行化
含义: 并行运行多个智能体以生成计划或输出,然后使用评判器/聚合器选择或组合最佳结果。
工作原理:
计划生成: 2 个或更多具有不同配置的智能体并行生成计划,评判器选择最佳
输出生成: 多个智能体并行生成最终输出,评判器基于质量、效率、错误倾向选择最佳
评判智能体: 使用评估标准(质量、正确性、效率)评估输出
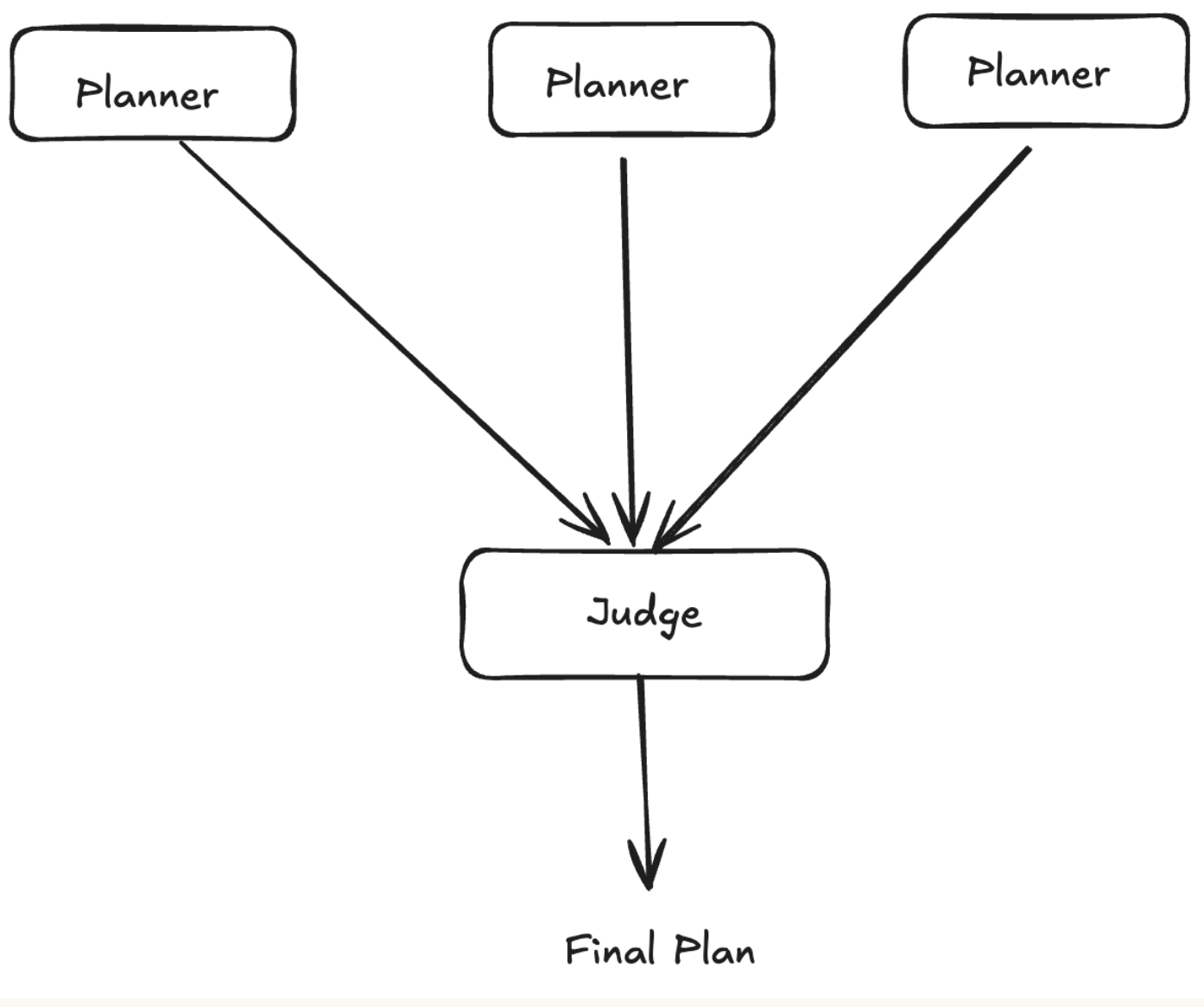
真实案例: Blackbox AI 使用这种方法进行代码生成任务。用户选择 2-5 个不同的模型(Claude、Codex、Gemini 或 Blackbox)并行处理同一任务。每个智能体在单独的 Git 分支中生成代码,AI 评判器根据质量、效率和错误倾向评估所有输出,以选择最佳实现。并行执行意味着延迟大致与单个智能体相同,而通过集成效应准确率显著提高。
对评估标准的影响:
成本: +2-5x(N 个智能体 × 每个智能体的成本 + 评判器成本)
延迟: +0-2s(并行执行意味着延迟 ≈ 最慢的智能体,但评判器增加开销)
准确率: +30-50%(集成效应,N 选一)
何时使用:
需要最高准确率的关键任务
当你有并行执行的预算时
输出质量差异较大的任务
对于简单任务或成本/延迟约束紧张时应避免使用
优化提示: 从 2-3 个智能体开始。收益递减很快出现。5 个智能体可能只比 3 个好 5-10%,但成本高 67%。
5. 使用文件系统维护状态
含义: 使用文件系统(markdown、文本文件或结构化格式)来维护状态、跟踪进度并在智能体调用之间提供上下文。
工作原理:
计划存储: 将初始计划作为待办事项列表写入文件
进度跟踪: 记录每个工具调用、其参数和结果
上下文构建: 使用文件作为后续智能体调用的上下文,保持对已完成工作的了解
状态持久化: 文件在智能体调用之间持久存在,实现可恢复的工作流
真实案例: Claude Code 广泛使用这种方法。它通过 markdown 文件维护持久状态,如 CLAUDE.md(项目规则和系统提示)、NOW.md(当前工作状态)、progress.md(执行日志)和 task_plan.md(即将到来的任务)。这些文件在会话之间持久存在,允许 Claude 恢复工作,保持对已完成工作的了解,并避免重复之前的步骤。文件系统充当智能体的记忆,每个文件在维护长期状态和项目连续性方面都有特定用途。
示例:
对评估标准的影响:
成本: +5-15%(略长的上下文窗口,但减少冗余工作)
延迟: +50-200ms(文件 I/O 开销,但实现更好的上下文)
准确率: +15-25%(更好的上下文感知,减少重复错误,实现恢复)
何时使用:
长时间运行、多步任务
当你需要可恢复的工作流时
之前步骤的上下文至关重要的任务
调试和可观察性需求
始终建议用于生产系统。开销最小,收益显著
额外好处:
支持人在回路工作流(人类可以审查/编辑文件)
提供审计跟踪和调试信息
允许部分执行和从失败中恢复
结论
构建生产就绪的智能体系统需要平衡成本、延迟和准确率。我们介绍的技术——如规划器-执行器架构、思维链、验证智能体、多个智能体和文件系统状态管理——是经过验证的构建块,以更高的延迟和费用为代价提高准确率。
关键要点:
从评估标准开始: 始终衡量成本、延迟和准确率。你无法优化你不衡量的东西。
从简单开始: 从最小可行架构开始。只在提供明确价值时才增加复杂性。
使用决策框架: 评估你的约束条件和任务复杂度以选择正确的技术。
战略组合: 技术协同工作得更好,但要注意累积成本。规划器-执行器架构通常是最佳的首选添加。
文件系统几乎总是值得的: 开销最小,收益(可观察性、调试、可恢复性)显著。
迭代和测量: 生产系统会演进。持续测量你的指标,并根据实际性能调整你的架构。
这里的技术构成了坚实的基础,但生产系统还有额外的考虑因素:错误处理、重试逻辑、速率限制、监控、安全性和可扩展性。这些将在第二部分中介绍,我们将深入研究运营关注点、优化策略和高级模式。
目前,从这五种技术开始,测量一切,并根据你的特定约束和要求进行迭代。框架是你的指南,但你的指标才是真相。